

One of the many things Futurelooks relies on is benchmark software. After all, it’s a good idea to measure performance differences when you upgrade parts in a system. Having peace of mind that the money was worth it is one of the functions that good benchmark software can provide and of the best benchmark software suites is now even better than before.
The lasted build of SiSoft Sandra 2013, SP5, adds new features and moves to a more neutral testing scheme. The latest testing suite has a Mult-buffer Hashing (SHA cryptography) test using the latest AVX and SSE4 instruction sets. This test simulates real world computer processes like virus scanning, client/server IPC, backups, file synchronization, etc. This new test should give end users a better idea of overall CPU performance in these cases.
In addition to the new testing scheme, Sandra 2013 SP5 also includes a number of bug fixes and moves away from an Intel compiler in certain tests. The latter is to ensure fairness when comparing AMD CPUs to their Intel counterparts. All of these changes are to ensure the most accurate and reliable test results as possible for future use.
The software looks like its moving in a good direction towards neutrality and we promise that you will see Sandra in future CPU/APU tests here.
[hide-this-part morelink=”Full Press Release”]
We are launching SP5 (19.58) for Sandra 2013 with a new features
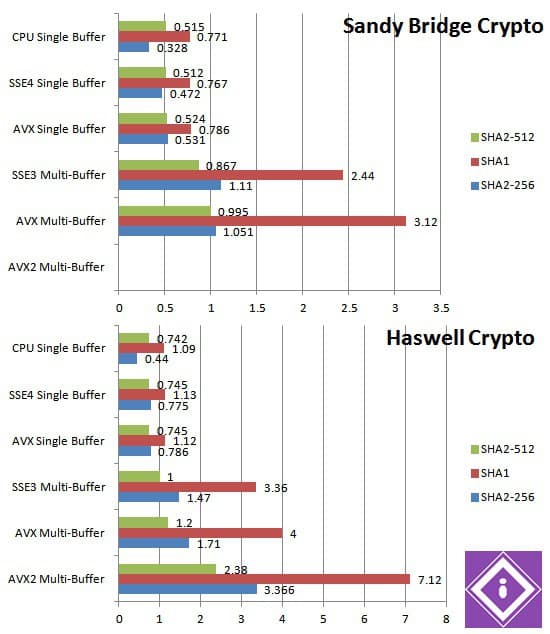
Benchmarks : Multi-Buffer Hashing Performance (SHA) through SIMD (AVX, SSE)
What are they?
A set of benchmarks designed to measure cryptographic performance in the most popular algorithms today: SHA family for hashing (e.g. key generation, signing, etc.). They allow us to show the importance of new instruction sets (AVX2, AVX, SSE4, and future AVX3) in accelerating cryptographic algorithms.
Why do we measure it?
Cryptography has become an important part of our digital life: it allows us to conduct safe transactions online, certify programs and services, keep our data secure and much more. The speed at which cryptographic operations (encryption, decryption, hashing, signing) can be performed is thus very much important.
What is multi-buffer hashing?
Multi-Buffer means that we operate on multiple buffers at the same time using SIMD instructions; i.e. instead of hashing 1 block at any one time, we can hash 2-8 blocks depending on the width of the SIMD register – similar to multi-media algorithms where we operate on multiple pixels at a time.
The major advantage is that – best case scenario – we improve performance by the number of blocks (e.g. 2x-8x) we operate at a time – a huge increase.
In “real life” scenarios, we would need to have multiple data buffers that need to be hash in order to realize this performance improvement – however there are many scenarios (e.g. client/server IPC, file change detection for backup/virus check/synchronization, etc.) where multiple buffers of data need to be hashed.
What do the results mean?
All results (encryption, decryption, hashing) results are in MB/s, i.e. how much data can be encrypted or decrypted per second. In all cases, as higher indexes mean better performance (MB/s) the higher the result the better the performance. We are comparing 3 processors are similar core and Turbo speeds – Turbo is enabled – for a “clock-for-clock” comparison. New models may run at higher (or lower) frequencies than the ones they replace, thus performance delta can vary.
List of new Features and Bug fixes
- New benchmark: Whetstone float (Native, Java, and .NET)
- In addition to Whetstone double (FP64) in FPU/SSE2/SSE3 we have added a float (FP32) to match the mobile versions of Sandra where double is generally aliased / emulated through floats.
- New support: Future instruction sets support AVX 512-bit (AVX512F/PF/EP), SHA HWA.
- AVX 512-bit float/double (FP32/FP64) (in Multi-Media, Multi-Core, Memory/Cache) will be released in the next update, once the tools are RTM. This may or may not be AVX3.x but is very similar to what “Phi” GPGPU (Knights Corner/Landing) supports.
- Note: We are not using any Intel compiler/tools to ensure fairness which is the reason for this delay. All code is assembler/intrinsics not automatically generated.
- Note2: integer operations will need to wait for a future update (AVX 3.1? 3.2?) just as with AVX; multi-buffer crypto thus won’t rival SHA HWA.
- SHA hashing acceleration (SHA1, SHA2-256 only, unfortunately SHA2-512 is not accelerated) will also be released in the next update, once the tools are RTM.
We’ve written a little article with more results to give you a better idea: http://www.sisoftware.co.uk/?d=qa&f=cpu_sha_hw
- “BayTrail” SoC: Various fixes and optimizations
- Some detection and optimization still pending, will be added later.
- “Kaveri” F16 APU : Various fixes and optimizations – thanks to John Ratsey
- Some detection and optimization still pending, will be added later.
- Note: Running on Hypervisor / VM and AVX512, AVX2/1, FMA3/4 instruction sets
Latest Hyper-V and some VMs do not enable OS-XSAVE, i.e. does not save/restore eXtended CPU mode – thus it is not possible for applications to use AVX512, AVX2/1, FMA3/4 instructions that use the 512/256-bit SIMD registers. It is done in order to facilitate VM migration across systems. It is not a bug, keep in mind if you don’t see Sandra using these instruction sets.
Projecting future instruction set performance is risky without the complex models manufacturers use (here Intel) – and even they may get a surprise when 1st silicon is tested for the first time! Here we assume that we will be limited by memory bandwidth when hashing large data blocks and the latencies of the SHA instructions will be negligible. On small blocks (cached), the performance is much harder to determine as instruction latencies may not be ignored.
Latencies for each SHA HWA Fx instruction have not been released at this time.
Even in this scenario we see SHA HWA being at least 10x faster than ALU implementations without requiring multi-buffers or advanced instruction sets. Let us hope they won’t be disabled on low-end/power CPUs (like AES, AVX) where it is needed most 😉
It should provide better performance than even AVX2 (~3x for AVX2-256) and even a future AVX512I (AVX3.x?) (~2x for AVX2-256) even though they operate on multiple buffers. But even if they turn out not to be much faster they will still be much faster than single-buffer SIMD versions which is what really counts.
Final Thoughts / Conclusions
While the programmability of CPUs is undoubtely their strength – fixed function implementations of (very) common algorithms is still a good idea where “real-time” (transparent) operation is required. AES HWA has undoubtedly brought transparent (i.e. no performance loss) full-disk encryption into the mainstream, SHA HWA will do the same for scenarios that depend on fast hashing of messages or data blocks (e.g. secure messaging, virus/integrity scanning, etc.)
Some may wonder about their impact on SHA-based BitCoin/LiteCoin currencies; unfortunately we do not have enough information to extrapolate that, but as these work on small blocks of data SHA HWA performance is unlikely to be limited by memory bandwidth. While a 4C/8T CPU may not rival a dedicated ASIC, more CPU cores become standard all the time (even phone CPUs have 8 cores now) – thus a 16C/64T desktop CPU would have massive SHA HWA bandwidth as long as the blocks fit in its (massive) L3 cache (20-32MB).
One more application would be Intel’s “Phi” GPGPU where SHA HWA would give those 62 cores massive aggregated small block hashing bandwidth.
We also see that a (future) 512-bit AVX integer instruction set would not outperform SHA HWA even when operating on 16 blocks! As the scenarious where we have 16 blocks of similar size to hash are not common, SHA HWA will always perform better.
[/hide-this-part]